

和 @AlphaArea 搞了一个大语言模型推理显卡天梯,这个天梯会根据现存速度来计算显卡用于推理的理论最大 token/s 的数值。因为LLM计算的本质就是扫内存,所以在相同模型大小下,扫的越快的显卡每秒钟输出token越多。
这里计算使用的是 llama-3.1-70b,该模型大约需要 48GB 的显存。对于显存不够的显卡假设他们使用无损耗的并行计算来进行推理(即总速度=单卡显存速度*显卡数量)。
从数据来看会发现单卡性能很强的情况(例如单卡A100),并不能得到碾压的推理速度,所以最好的推理方案仍然是多卡并行。
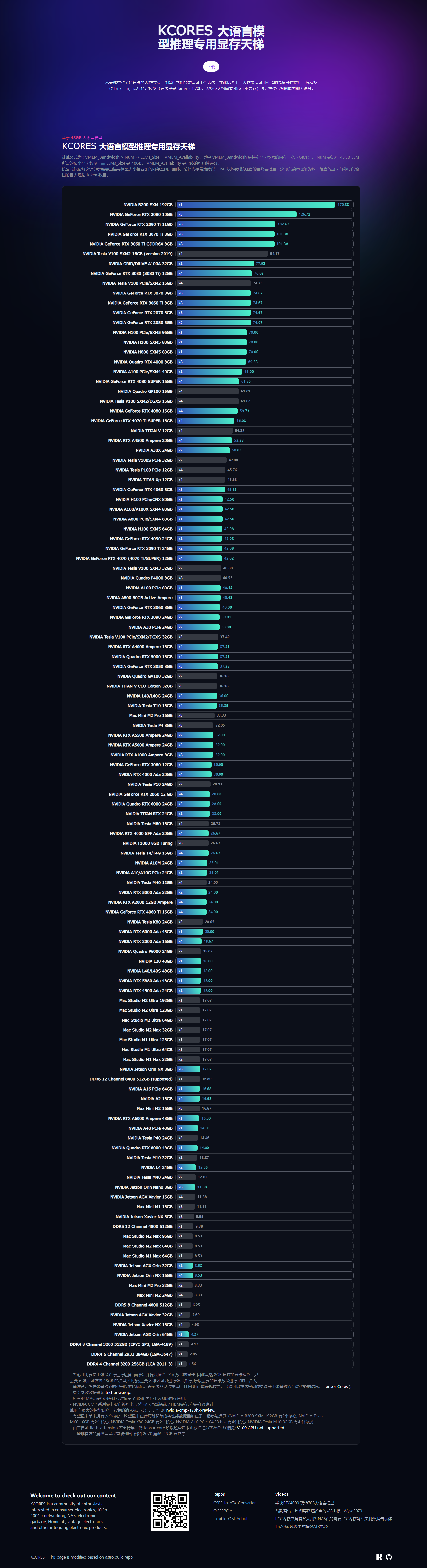
分数与实际推理速度差距的话,Mac M2 Ultra 128G 实测是13tps, 这里计算得出的是17tps. 有其他设备的老铁可以也晒一晒自己的tps, 看看跟理论值的差距有多大.
另外排行榜还加入了DDR5和DDR6的假设性能数值, 如果DDR6能飙得比8600还高得话, 还是能用一用的. DDR4就别想了, 用起来十分痛苦.
详细可以访问网站:https://vmem-for-llms.kcores.com
2
deleted by creator
另外需要注意的是:
- 不要买Jetson, 虽然显存大, 但是带宽惨不忍睹. 会卡到死.
- 如果不想垃圾佬(考虑二手残值), 买Mac M2 Ultra是靠谱的选择. MLX目前支持的LLM列表可以在这里找到, 而且我在Twitter上follow的MLX的两个核心贡献者, 他们对新LLM的支持还是挺快的: https://huggingface.co/mlx-community
6
