

NVIDIA 刚刚发布了他们魔改后的 llama-3.1-nemotron-70b-instruct, 据说比GPT-4o和Sonnet-3.5要猛, 不过一部分用户测试后发现这个模型应该只是跑分友好的, 倾向于生成更短的答案来得高分.
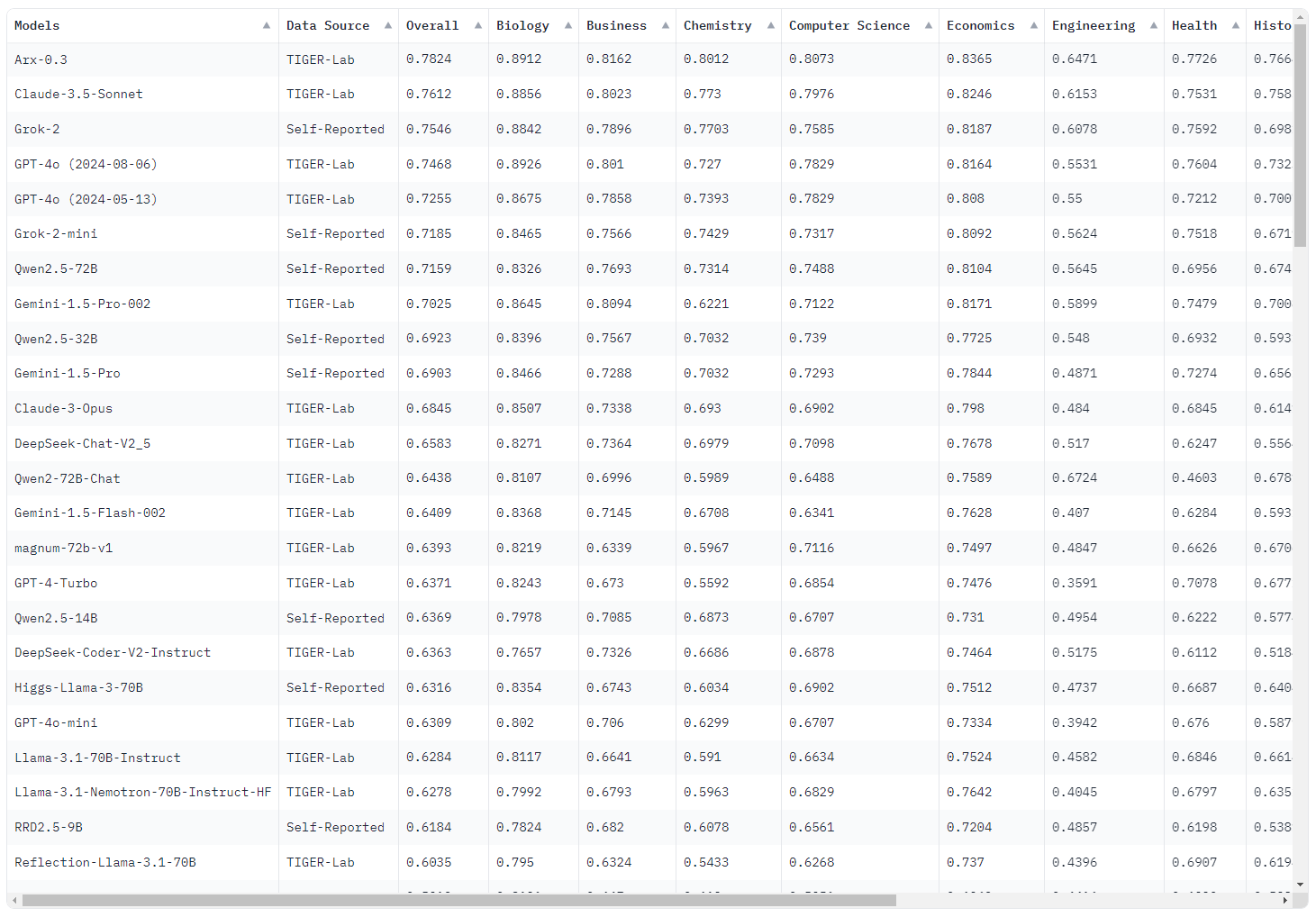
而具体跑分来看, 甚至比原本的 Llama-3.1-70b-instruct 分数还低… (不同测试可能有不同倾向, 这个是 MMLU-Pro 的测试结果)
0
NVIDIA 刚刚发布了他们魔改后的 llama-3.1-nemotron-70b-instruct, 据说比GPT-4o和Sonnet-3.5要猛, 不过一部分用户测试后发现这个模型应该只是跑分友好的, 倾向于生成更短的答案来得高分.
而具体跑分来看, 甚至比原本的 Llama-3.1-70b-instruct 分数还低… (不同测试可能有不同倾向, 这个是 MMLU-Pro 的测试结果)