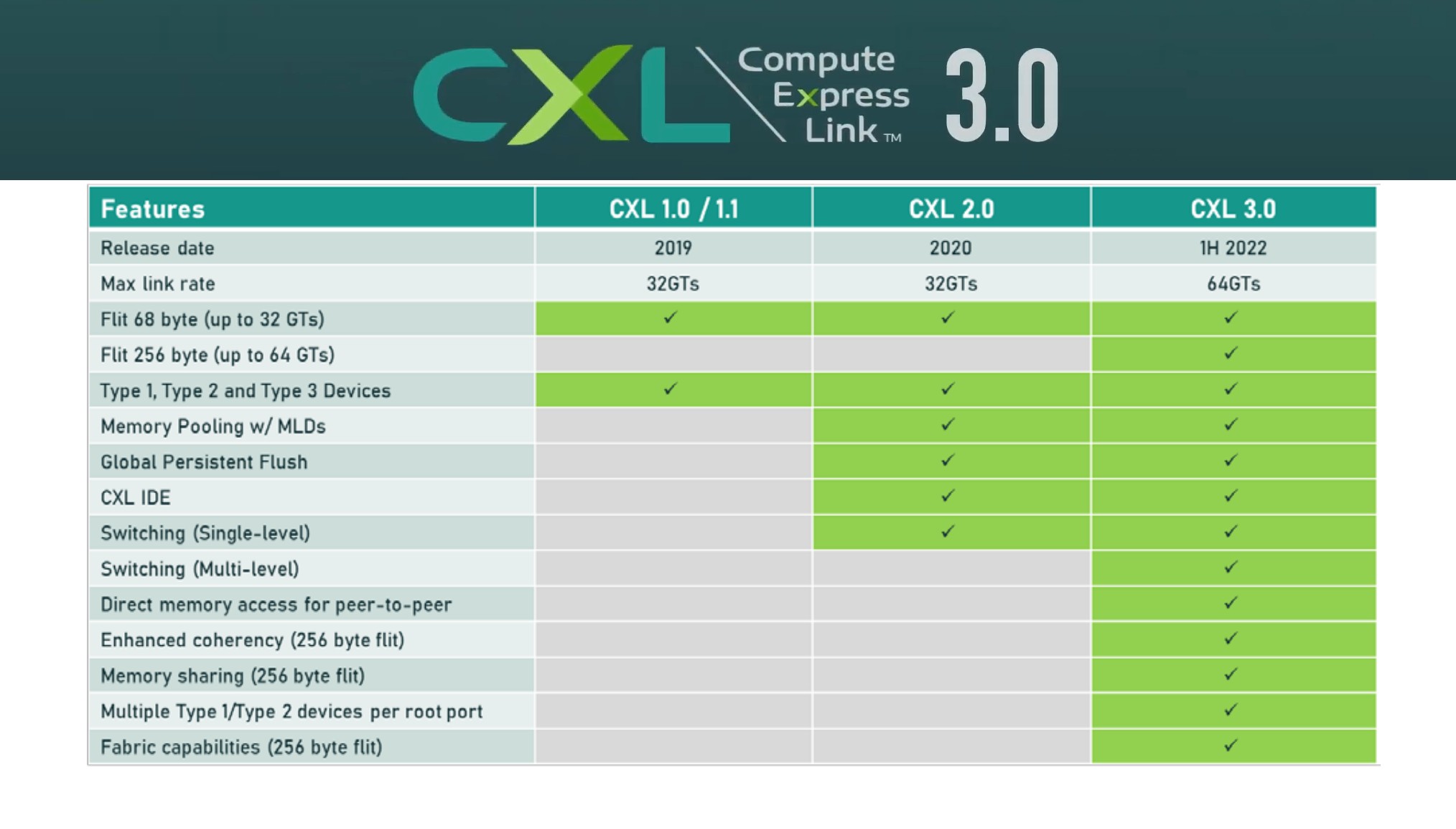
简单来讲 CXL 是一种新的开放标准,适用于高速, 高容量中央处理单元 (CPU) 到设备以及 CPU 到内存的连接, 这是一个由英特尔领导的联盟, 由多家技术公司共同创建一个标准.

(图片来自STH)
CXL 基于 PCIe, 分为三种协议:
- CXL.io (块输入/输出协议)
- CXL.cache (访问系统内存的缓存一致性协议)
- CXL.mem (访问设备内存的缓存一致性协议)
不过目前能看到的最有效的应用还是 内存池 on PCIe 这种模式. 比如上图中的 Astera Labs 的 Aurora A1000.
其实 PCIe 上面弄个 FPGA 然后连接内存当块存储本身现有技术就是可以实现的, 而这里 CXL 协议更多的是起到缓存一致的作用, 即CPU可以直接将该设备当作内存使用, 而不是块设备, 去走块存储的一整套协议和内核协议栈等. 因此相关CPU的负载全都可以offload到卡上去做. 这样带来的收益有两个:
- 增加最大可用内存上限
- 减少CPU使用
然后? 然后就没有然后了.
Astera Labs 在今年的 FMS 峰会上的 PPT 内容全是关于 LLM 的, 下面来看一下他们的PPT截图:
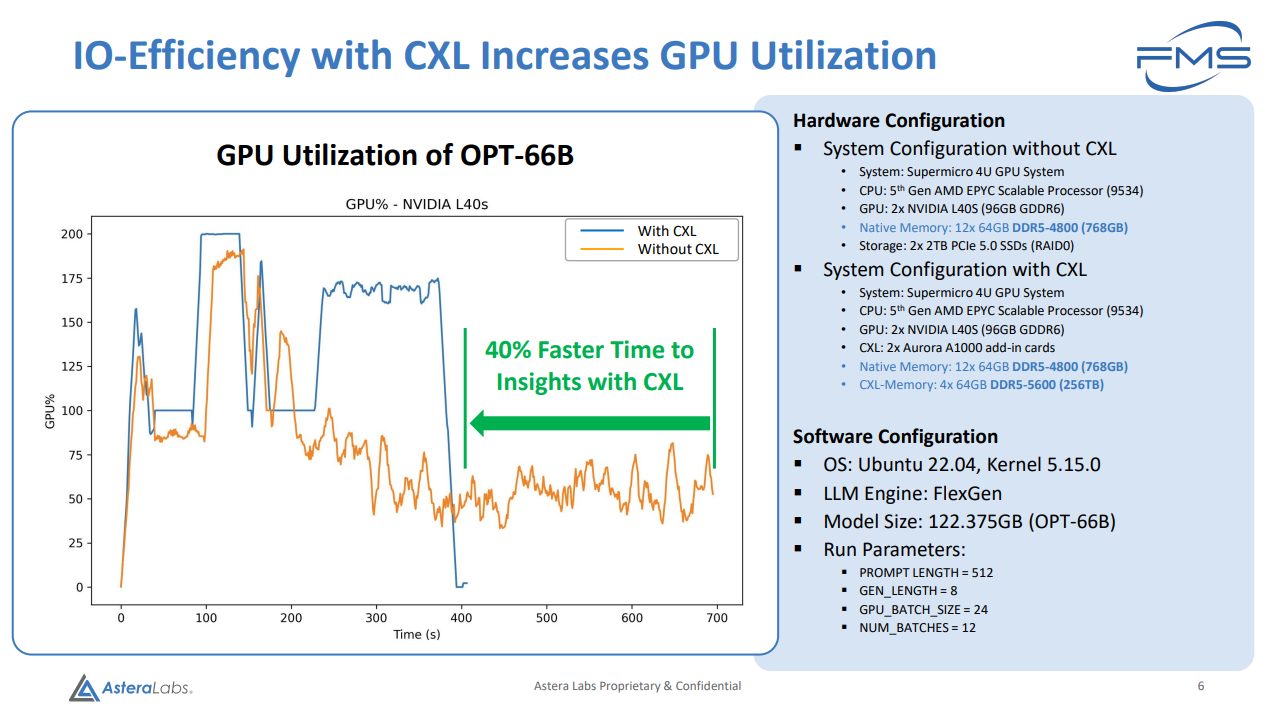
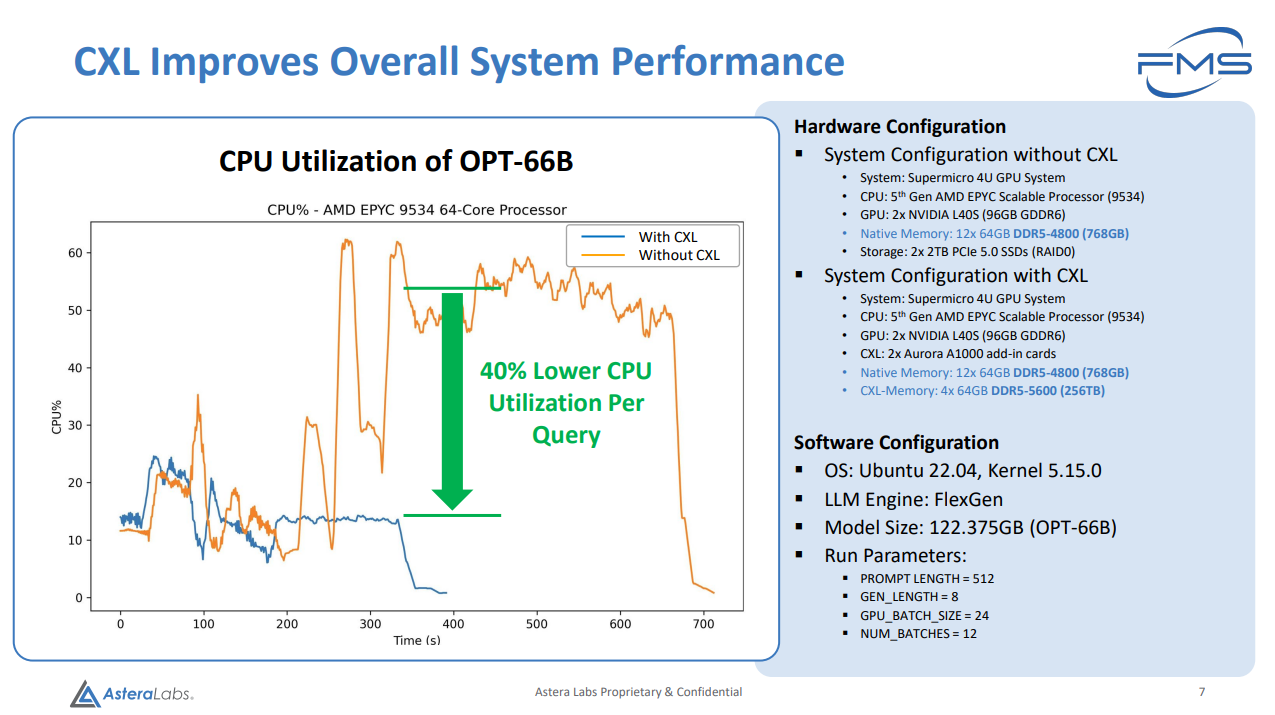
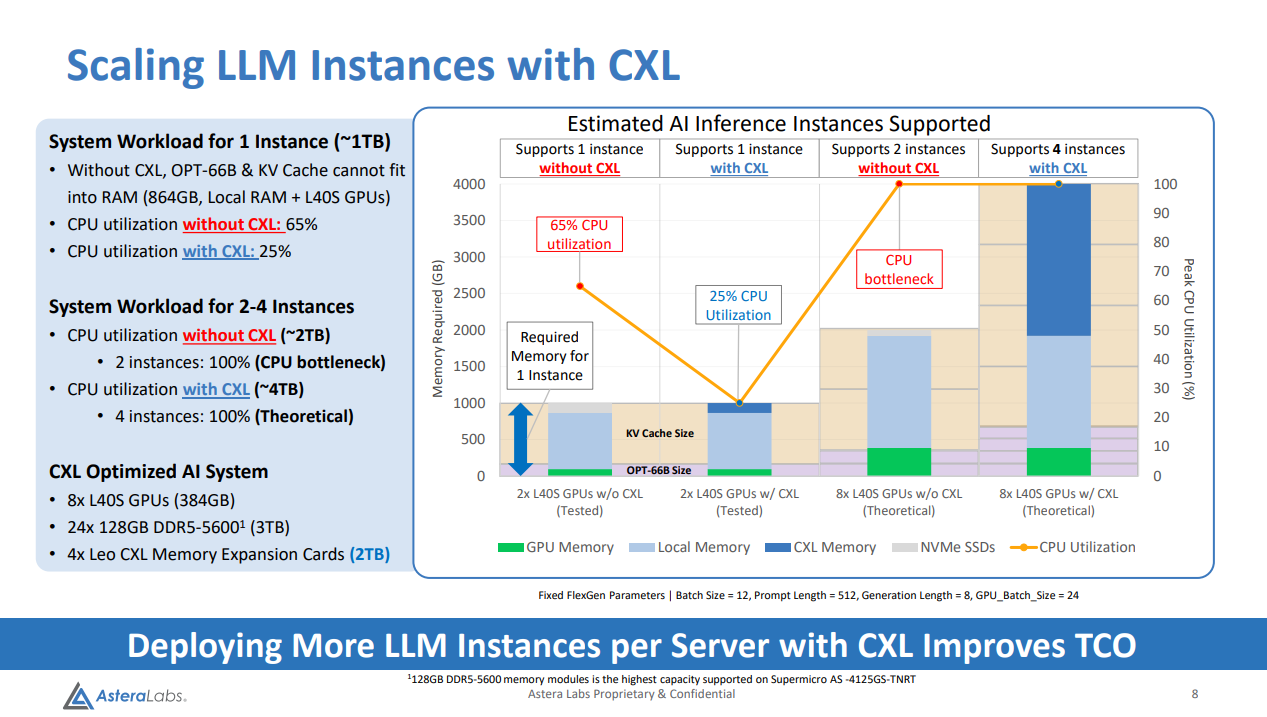
提升了 TTI(从提问到得到了有价值的答案时间), 减少了CPU使用, 增加了最大实例数量.
后两个可能对企业大规模应用有一定的价值. 但是第一个, 提升了 TTI 是如何做到的? 通过第一个 PPT 我们不难发现是把 2 个 RAID0 的 2TB NVMe SSD 换成了 256G 的 CXL 内存 (PPT 中这里甚至有笔误, 写成了256TB). 那我直接在机器上多插 256G 内存, 会不会比这个来的快? 成本比这个还小? (鸡贼的是机器用的内存是 DDR5-4800, 然后 Aurora A1000 上插的是 DDR5-5600…).
那么, 代价是什么? 缓存一致是个非常复杂的课题, 可能对整个生产环节都有挑战, 甚至存储架构, 编译器, 应用程序都要针对这个新增的设备进行特殊优化 (如同 DCPMM, 直接插上当硬盘是没那么靠谱的).
综上, 如果有垃圾可以玩还是可以试试的. 但整体而言给我的感觉是 intel DCPMM 没搞成的另一个押宝. 对于LLM应用, 显存带宽就是一切. 全都能装进显存计算是王道. 其次才是机器内存. 再次才是这玩意.
Refs